 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTechniques for effective vocabulary selection
Jun 04, 2003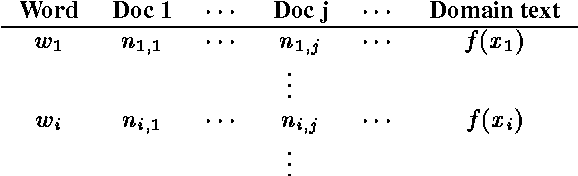
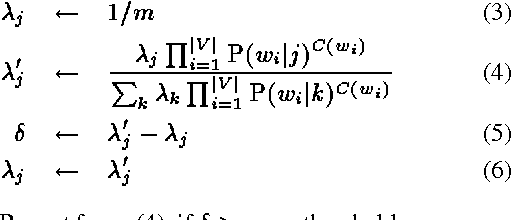
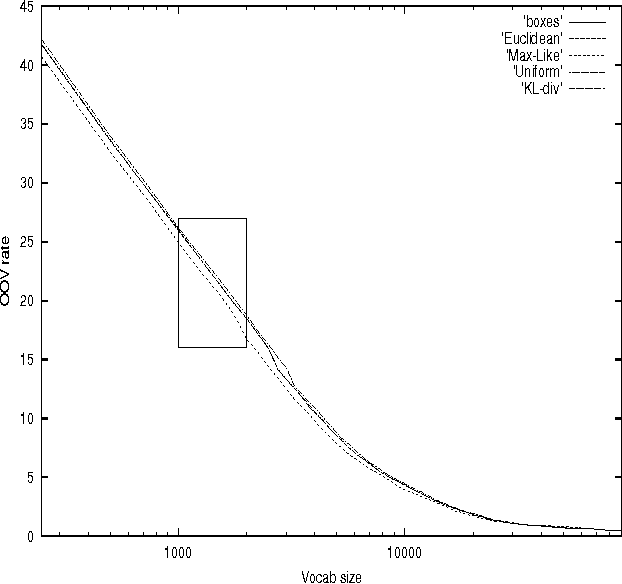
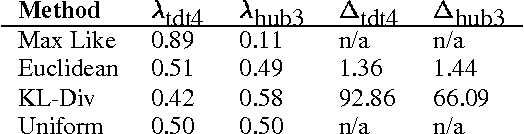
The vocabulary of a continuous speech recognition (CSR) system is a significant factor in determining its performance. In this paper, we present three principled approaches to select the target vocabulary for a particular domain by trading off between the target out-of-vocabulary (OOV) rate and vocabulary size. We evaluate these approaches against an ad-hoc baseline strategy. Results are presented in the form of OOV rate graphs plotted against increasing vocabulary size for each technique.
A Statistical Model for Word Discovery in Transcribed Speech
Nov 30, 2001A statistical model for segmentation and word discovery in continuous speech is presented. An incremental unsupervised learning algorithm to infer word boundaries based on this model is described. Results of empirical tests showing that the algorithm is competitive with other models that have been used for similar tasks are also presented.
* Expanded version of ICML-01 paper (pp.569--576)
A procedure for unsupervised lexicon learning
Nov 30, 2001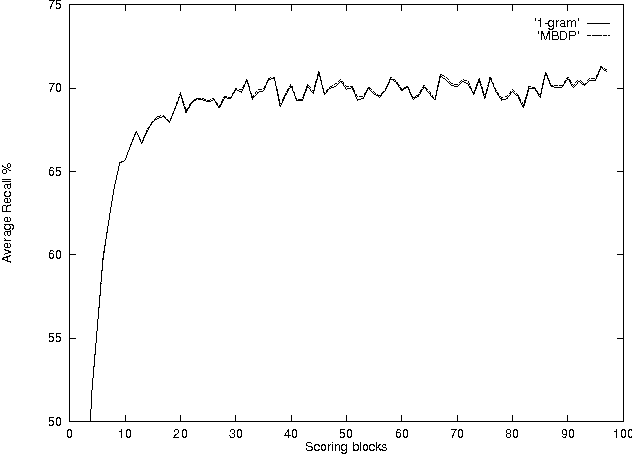
We describe an incremental unsupervised procedure to learn words from transcribed continuous speech. The algorithm is based on a conservative and traditional statistical model, and results of empirical tests show that it is competitive with other algorithms that have been proposed recently for this task.
* Expanded version of this paper appears in Computational Linguistics 27(3)
MAP Lexicon is useful for segmentation and word discovery in child-directed speech
Oct 14, 1999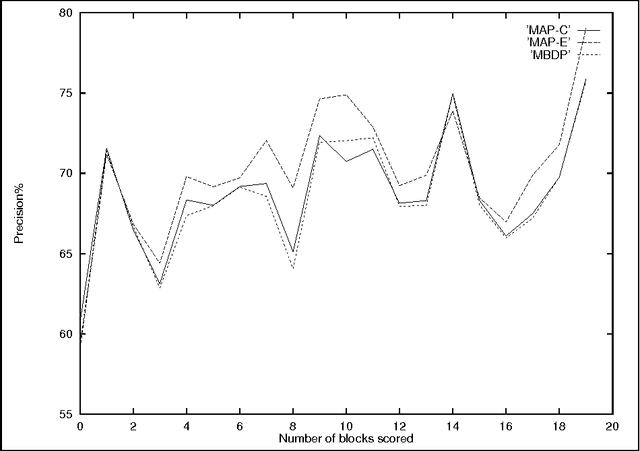
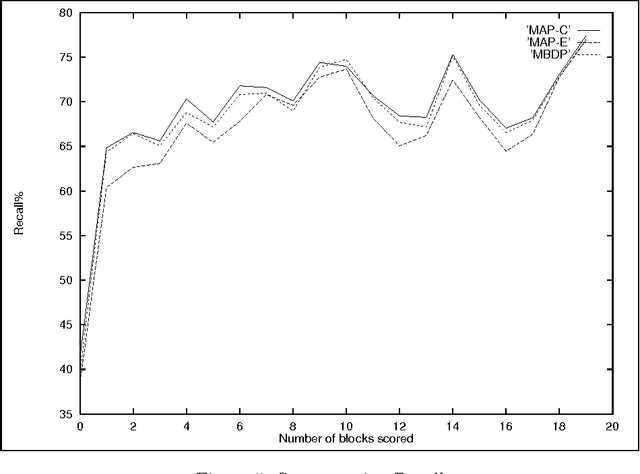
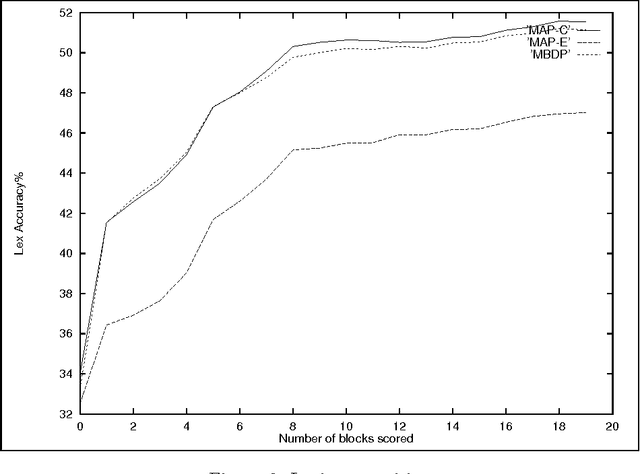
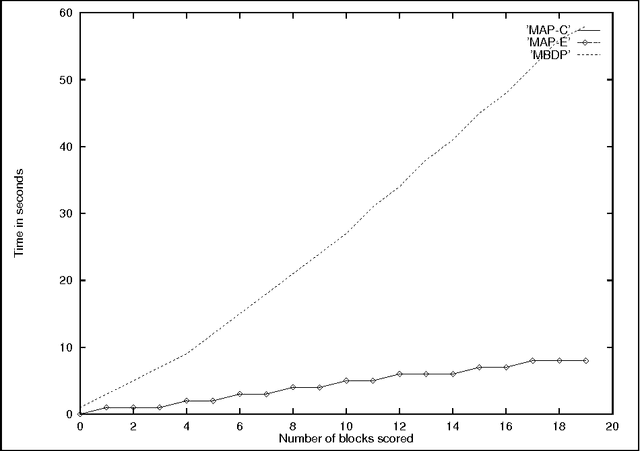
Because of rather fundamental changes to the underlying model proposed in the paper, it has been withdrawn from the archive.
A statistical model for word discovery in child directed speech
Oct 13, 1999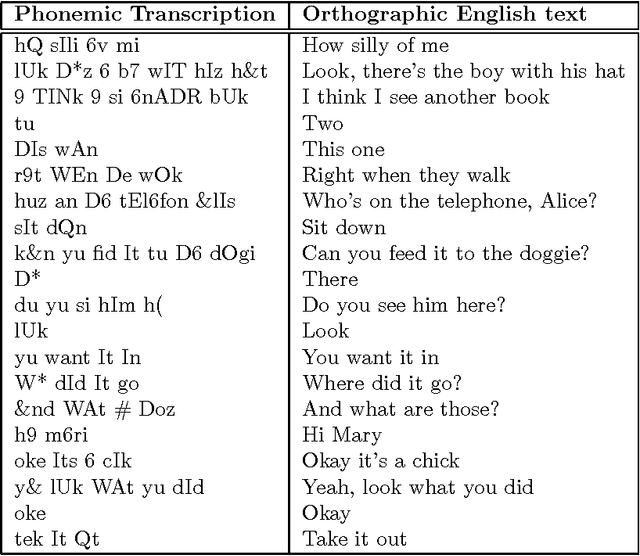


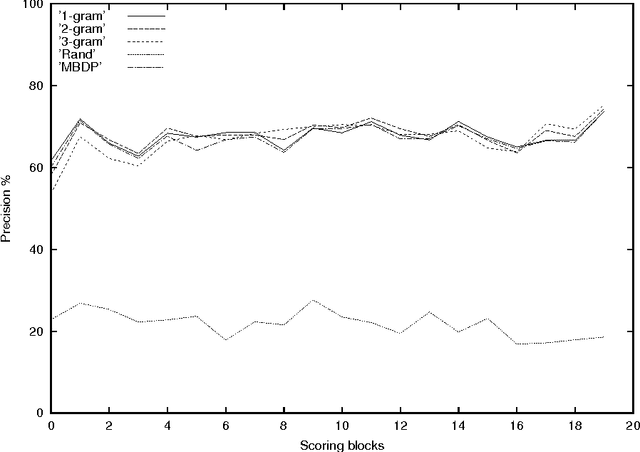
A statistical model for segmentation and word discovery in child directed speech is presented. An incremental unsupervised learning algorithm to infer word boundaries based on this model is described and results of empirical tests showing that the algorithm is competitive with other models that have been used for similar tasks are also presented.